
Abstract
We introduce Fact-Hash, a novel parameter encoding method for training on-device neural radiance fields. Neural Radiance Fields (NeRF) have proven pivotal in 3D representations, but their applications are limited due to large computational resources. On-device training can open large application fields, providing strength in communication limitations, privacy concerns, and fast adaptation to a frequently changing scene. However, challenges such as limited resources (GPU memory, storage, and power) impede their deployment. To handle this, we introduce Fact-Hash, a novel parameter-encoding merging Tensor Factorization and Hash-encoding techniques. This integration offers two benefits: the use of rich high-resolution features and the few-shot robustness. In Fact-Hash, we project 3D coordinates into multiple lower-dimensional forms (2D or 1D) before applying the hash function and then aggregate them into a single feature. Comparative evaluations against state-of-the-art methods demonstrate Fact-Hash’s superior memory efficiency, preserving quality and rendering speed. Fact-Hash saves memory usage by over onethird while maintaining the PSNR values compared to previous encoding methods. The on-device experiment validates the superiority of Fact-Hash compared to alternative positional encoding methods in computational efficiency and energy consumption. These findings highlight Fact-Hash as a promising solution to improve feature grid representation, address memory constraints, and improve quality in various applications.
TL;DR:
We propose a novel way to seamlessly integrate hash encoding and Tensor Factorization based encoding methods to leverage their strengths and achieve synergy effects. Our method introduces efficient position encoding which demonstrates parameter efficiency and stability in on-device neural rendering.
Schematic Overview
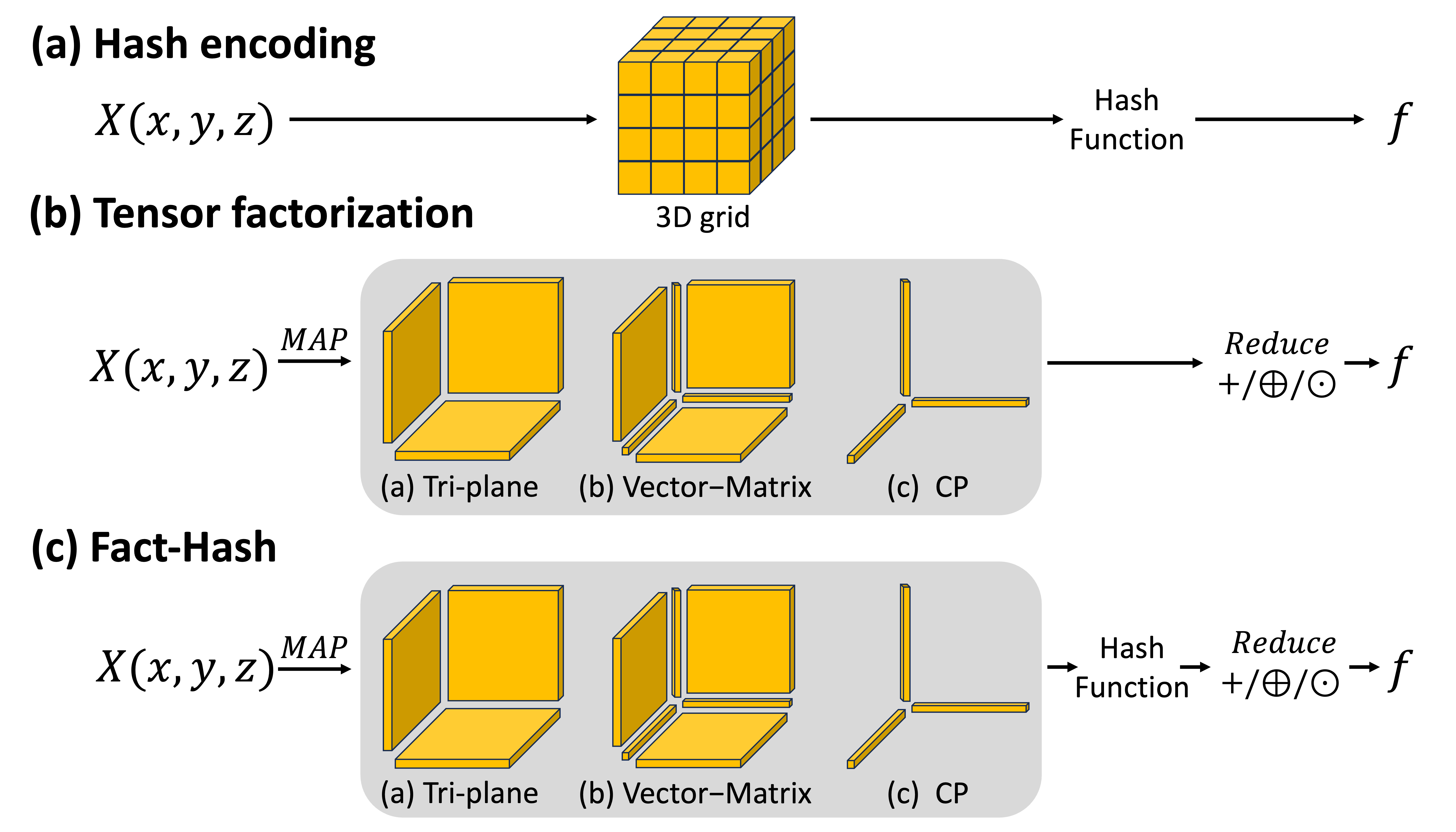
Experimental Results

The superiority of our model is better demonstrated in the learned bitfield results. Other methods show more inaccurate overfitted bitfield results occurring floating artifacts. In comparison, our model learned object-tight opacity in most scenes, which demonstrate the robustness of our model, while maintaining high compactness and expressiveness.
Video Results
Bibliography
Acknowledgements
This work was supported by Institute of Information \& communications Technology Planning \& Evaluation (IITP) grant (No.RS-2022-II220290, Visual Intelligence for Space-Time Understanding and Generation based on Multi-layered Visual Common Sense; No.RS-2019-II191906, Artificial Intelligence Graduate School Program(POSTECH)) and National Research Foundation of Korea (NRF) grant (No. RS-2024-00358135, Corner Vision: Learning to Look Around the Corner through Multi-modal Signals) funded by the Korea government(MSIT). A portion of this work was carried out during an internship at NAVER AI Lab.